Lecture 2: How Machine Learning Works
In this lecture, we will understand how machine learning works in medicine.
We will focus on intuition, not mathematics.
The goal is to understand how AI learns—and where it can fail.

By the end of this lecture, you should understand how machine learning models are trained, how they are evaluated, and why they sometimes fail in real clinical settings.
Machine learning is a way for computers to learn patterns from data and use those patterns to make predictions.

In supervised learning, the model learns from examples where both the input and the correct answer are known.
For example, patient data is used to predict whether the patient survived.

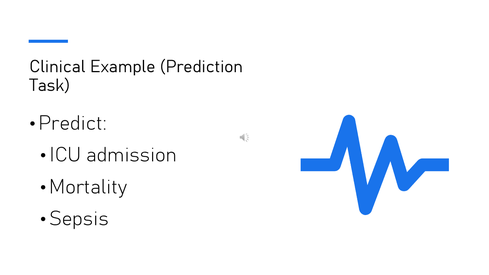
In medicine, machine learning is often used to predict outcomes, such as ICU admission or mortality risk.
To build a reliable model, we divide data into three parts: training, validation, and test sets.
Each part has a different role.

The training set is used to teach the model.
It learns patterns from the data by seeing many examples with known outcomes.
For example, the model learns which patient features are associated with survival or disease.

The validation set is used to adjust the model during the learning process.
It helps improve performance by testing how well the model works on data that it has not seen during training.
This helps us avoid overfitting, which means learning the training data too specifically.

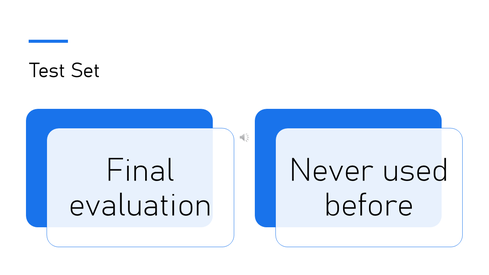
The test set is used only once at the end.
It represents new patients and tells us how the model performs in real life.
Overfitting occurs when the model learns the training data too well.
It even learns patterns that are not truly meaningful, such as noise that exists only in the training data.
As a result, the model may perform very well on the training data, but poorly on new patients.

A good model generalizes well.
This means it performs well not only on the training data, but also on new, unseen patients.
It can also work reliably in different clinical settings, such as another hospital.

A model trained in one hospital may not work well in another hospital.
This can happen because patient populations, clinical practices, and data collection methods are different.
These differences can lead to problems such as data bias, overfitting, and insufficient validation.

There are several common pitfalls in medical AI.
First, data bias. This occurs when the training data does not represent the full patient population.
For example, if the data comes mostly from one group of patients, the model may not perform well for others.
Second, overfitting. This happens when the model learns the training data too specifically, including patterns that are not meaningful.
As a result, it performs poorly on new patients.
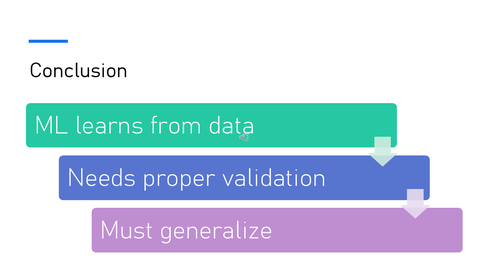
Third, poor validation. This means the model has not been properly tested on independent data.
Without proper validation, we cannot be confident that the model will work in real clinical practice.

Machine learning learns from data, but its performance depends on how it is trained and evaluated.
Generalization is essential for safe clinical use.